Global Biases Diagnostic
Description
The GlobalBiases diagnostic is a set of tools for the analysis and visualization of 2D spatial biases in climate model outputs. It supports comparative analysis between a target dataset (typically a climate model) and a reference dataset, commonly an observational or reanalysis product such as ERA5. Alternatively, it can be used to compare outputs from two different model simulations, for example to assess differences between historical and scenario experiments.
GlobalBiases provides tools to plot:
Climatology maps
Bias maps
Seasonal bias maps
Vertical profiles to assess biases across pressure levels
Classes
There are three classes in the diagnostic:
GlobalBiases: retrieves the data and prepares it for plotting (e.g., regridding, pressure level selection, unit conversion). It handles the computation of mean climatologies, including seasonal climatologies if requested. Climatologies are saved as class attributes and as NetCDF files.
PlotGlobalBiases: provides methods for plotting the global biases, seasonal biases, and vertical profiles. It generates the plots based on the data prepared by the GlobalBiases class.
StatGlobalBiases: statistical class including methods to compute global bias statistics and to assess the statistical significance of the bias. It computes global bias statistics such as mean bias and root mean square error (RMSE) between the model and reference datasets (area-weighted if grid cell areas are provided). It also performs a two-sample t-test at each grid point to determine if the difference between model and reference data is statistically significant.
File structure
The diagnostic is located in the
aqua/diagnostics/global_biasesdirectory, which contains both the source code and the command line interface (CLI) script.A template configuration file is available at
aqua/diagnostics/templates/diagnostics/config-global_biases.yamlNotebooks are available in the
notebooks/diagnostics/global_biasesdirectory and contain examples of how to use the diagnostic.
Input variables and datasets
By default, the diagnostic compares against the ERA5 dataset, but it can be configured to use any other dataset as a reference.
A list of the variables that are compared automatically when running the full diagnostic is provided in the configuration files
available in the aqua/diagnostics/config/diagnostics/global_biases directory.
Some of the variables that are typically used in this diagnostic are:
2t(2 metre temperature)tprate(total precipitation rate)msl(mean sea level pressure)u,v(zonal and meridional wind)q(specific humidity)
The diagnostic is designed to work with data from the Low Resolution Archive (LRA), generated by the Data reduction OPerator (DROP) of the AQUA project, which provides monthly data at a 1x1 degree resolution. A higher resolution is not necessary for this diagnostic.
Basic usage
The basic usage of this diagnostic is explained with a working example in the notebook. The basic structure of the analysis is the following:
from aqua.diagnostics import GlobalBiases, PlotGlobalBiases
biases_ifs_nemo = GlobalBiases(
model='IFS-NEMO',
exp='historical-1990',
source='lra-r100-monthly',
loglevel="DEBUG"
)
biases_era5 = GlobalBiases(
model='ERA5',
exp='era5',
source='monthly',
loglevel="DEBUG"
)
biases_ifs_nemo.retrieve(var='q')
biases_ifs_nemo.compute_climatology(seasonal=True, areas=True)
biases_era5.retrieve(var='q')
biases_era5.compute_climatology(seasonal=True, areas=True)
pg = PlotGlobalBiases(loglevel='DEBUG')
pg.plot_bias(data=biases_ifs_nemo.climatology, data_ref=biases_era5.climatology, var='q', plev=18000,
area=biases_ifs_nemo.climatology['cell_area'], show_stats=True,
# Statistical significance options
show_significance=True, # Enable significance stippling
significance_alpha=0.05, # 95% confidence level
stipple_density=None, # If None, computed adaptively based on grid resolution
target_spacing_deg=2 # Target spacing in degrees for stippling
stipple_size=0.8, # Size of stipple dots
invert_stippling=False, # False = stipple where differences ARE significant
)
Note
Start/end dates and reference dataset can be customized. If not specified otherwise, plots will be saved in PNG and PDF format in the current working directory.
CLI usage
The diagnostic can be run from the command line interface (CLI) by running the following command:
cd $AQUA/aqua/diagnostics/global_biases
python cli_global_biases.py --config <path_to_config_file>
Additionally, the CLI can be run with the following optional arguments:
--config,-c: Path to the configuration file.--nworkers,-n: Number of workers to use for parallel processing.--cluster: Cluster to use for parallel processing. By default a local cluster is used.--loglevel,-l: Logging level. Default isWARNING.--catalog: Catalog to use for the analysis. Can be defined in the config file.--model: Model to analyse. Can be defined in the config file.--exp: Experiment to analyse. Can be defined in the config file.--source: Source to analyse. Can be defined in the config file.--outputdir: Output directory for the plots.--startdate: Start date for the analysis.--enddate: End date for the analysis.
Configuration file structure
The configuration file is a YAML file that contains the details on the dataset to analyse or use as reference, the output directory and the diagnostic settings. Most of the settings are common to all the diagnostics (see Diagnostics configuration files). Here we describe only the specific settings for the global biases diagnostic.
globalbiases: a block (nested in thediagnosticsblock) containing options for the Global Biases diagnostic. Variable-specific parameters override the defaults.run: enable/disable the diagnostic.diagnostic_name: name of the diagnostic.globalbiasesby default, but can be changed when the globalbiases CLI is invoked within anotherrecipediagnostic, as is currently done forRadiation.variables: list of variables to analyse.formulae: list of formulae to compute new variables from existing ones (e.g.,tnlwrf+tnswrf).plev: pressure levels to analyse for 3D variables.seasons: enable seasonal analysis.seasons_stat: statistic to use for seasonal climatology (e.g., “mean”).vertical: enable vertical profiles.startdate_data/enddate_data: time range for the dataset.startdate_ref/enddate_ref: time range for the reference dataset.
globalbiases:
run: true
diagnostic_name: 'globalbiases'
variables: ['tprate', '2t', 'msl', 'tnlwrf', 't', 'u', 'v', 'q', 'tos']
formulae: ['tnlwrf+tnswrf']
params:
default:
plev: [85000, 20000]
seasons: true
seasons_stat: 'mean'
vertical: true
startdate_data: null
enddate_data: null
startdate_ref: "1990-01-01"
enddate_ref: "2020-12-31"
tnlwrf+tnswrf:
short_name: "tnr"
long_name: "Top net radiation"
plot_params: defines colorbar palette and limits and projection parameters for each variable.show_statsenables the display of global bias statistics (mean bias and RMSE) on the global bias plot.show_significanceenables the display of stippling to indicate where the bias is statistically significant, based on a two-sample Welch t-test (significance_alphadefines the confidence level, e.g., 0.05 for 95% confidence). The stippling density can be set explicitly viastipple_density, or left unset to trigger an adaptive mode that automatically computes the stipple density based on the grid resolution and the target spacing in degrees (target_spacing_deg). This ensures readable stippling across different resolutions, from coarse grids such as r100 to high-resolution ones such as hpz10.
The default parameters are used if not specified for a specific variable. Refer to AQUA/aqua/core/util/projections.py for available projections.
- plot_params:
- default:
projection: ‘robinson’ projection_params: {} show_stats: true show_significance: true # Enable significance stippling significance_alpha: 0.05 # 95% confidence level stipple_density: null # If null, computed adaptively target_spacing_deg: 2 # Target spacing in degrees for stippling
- 2t:
cmap: ‘RdBu_r’ vmin: -15 vmax: 15
- msl:
vmin: -1000 vmax: 1000
- u:
vmin_v: -50 vmax_v: 50
Output
The diagnostic produces four types of plots:
Global climatology maps
Global bias maps (model vs reference)
Seasonal bias maps
Vertical bias profiles (for 3D variables)
Plots are saved in both PDF and PNG format. Data outputs are saved as NetCDF files.
Observations
The default reference dataset is ERA5 reanalysis, provided by ECMWF.
The diagnostic uses ERA5 monthly averages at 1x1 degree resolution from the AQUA obs catalog (model=ERA5, exp=era5, source=monthly).
Custom reference datasets can be configured in the configuration file.
Example Plots
All plots can be reproduced using the notebooks in the notebooks directory on LUMI HPC.
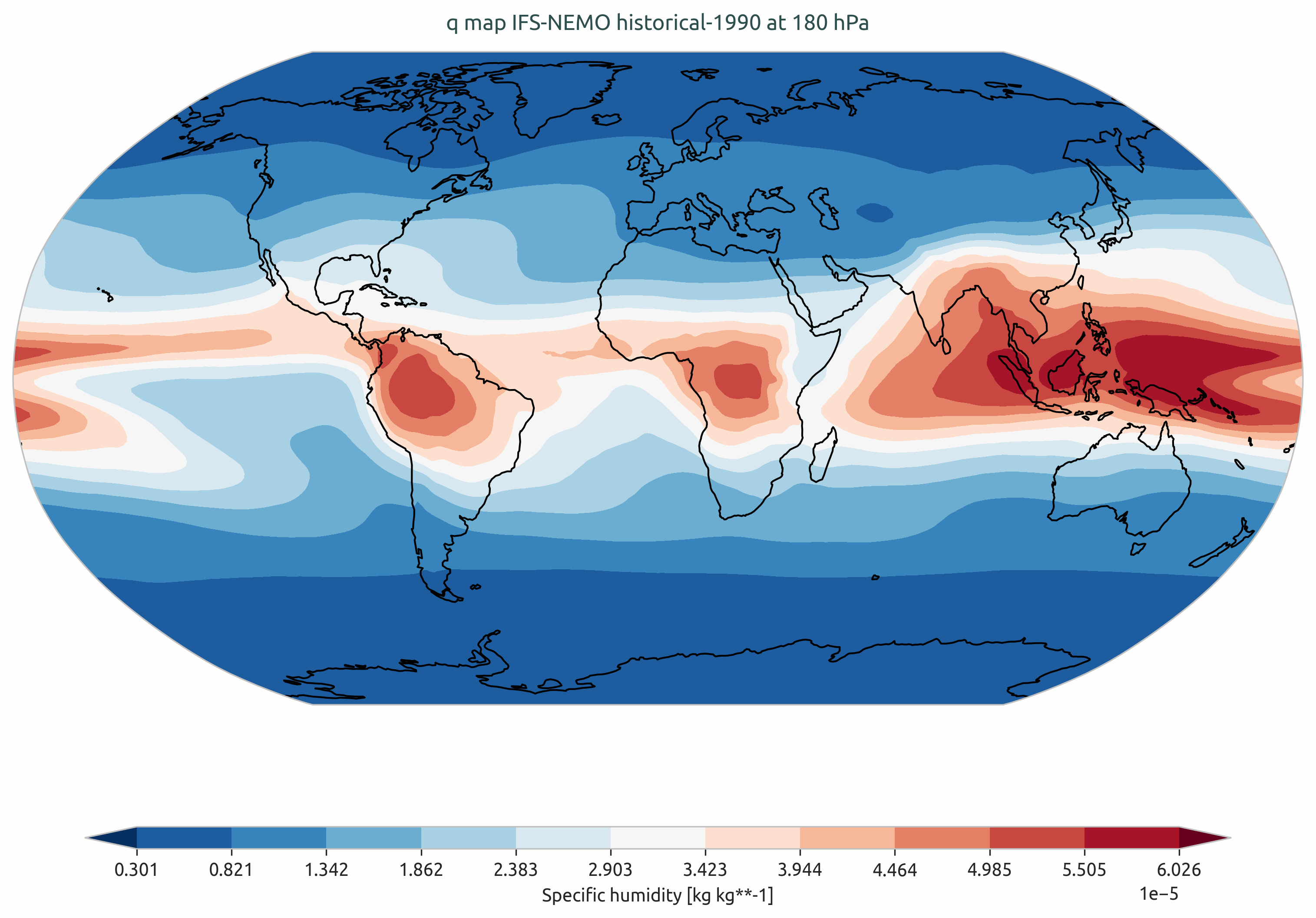
Climatology of q from IFS-NEMO historical-1990.
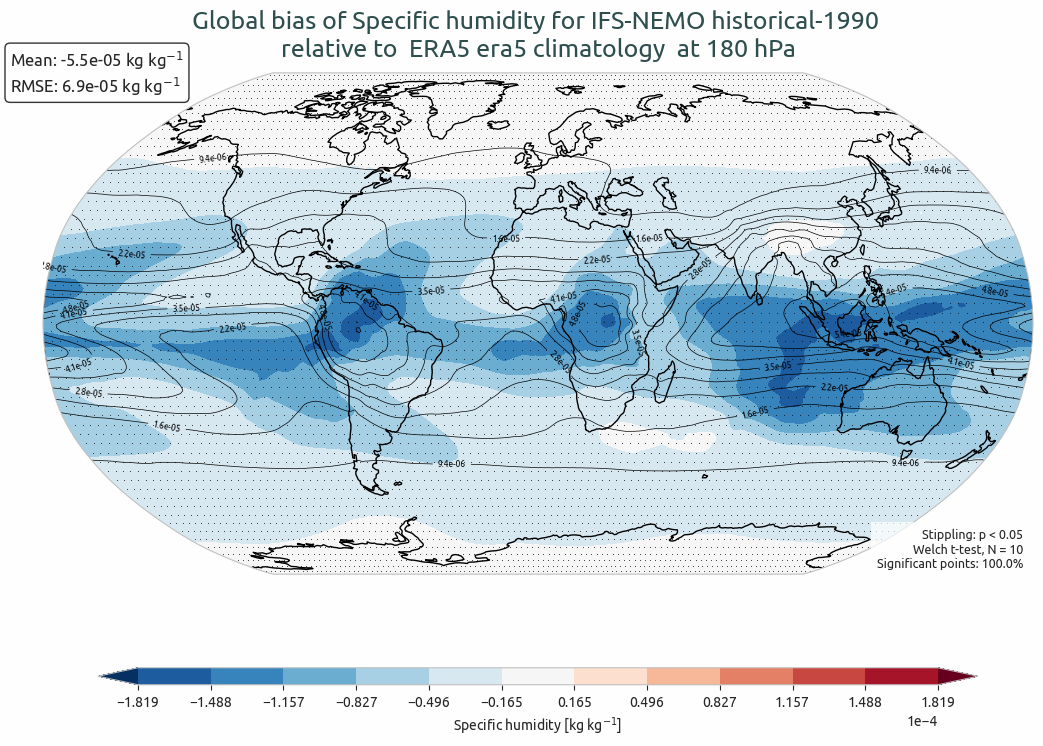
Global bias of q from IFS-NEMO historical-1990 with respect to ERA5 climatology.
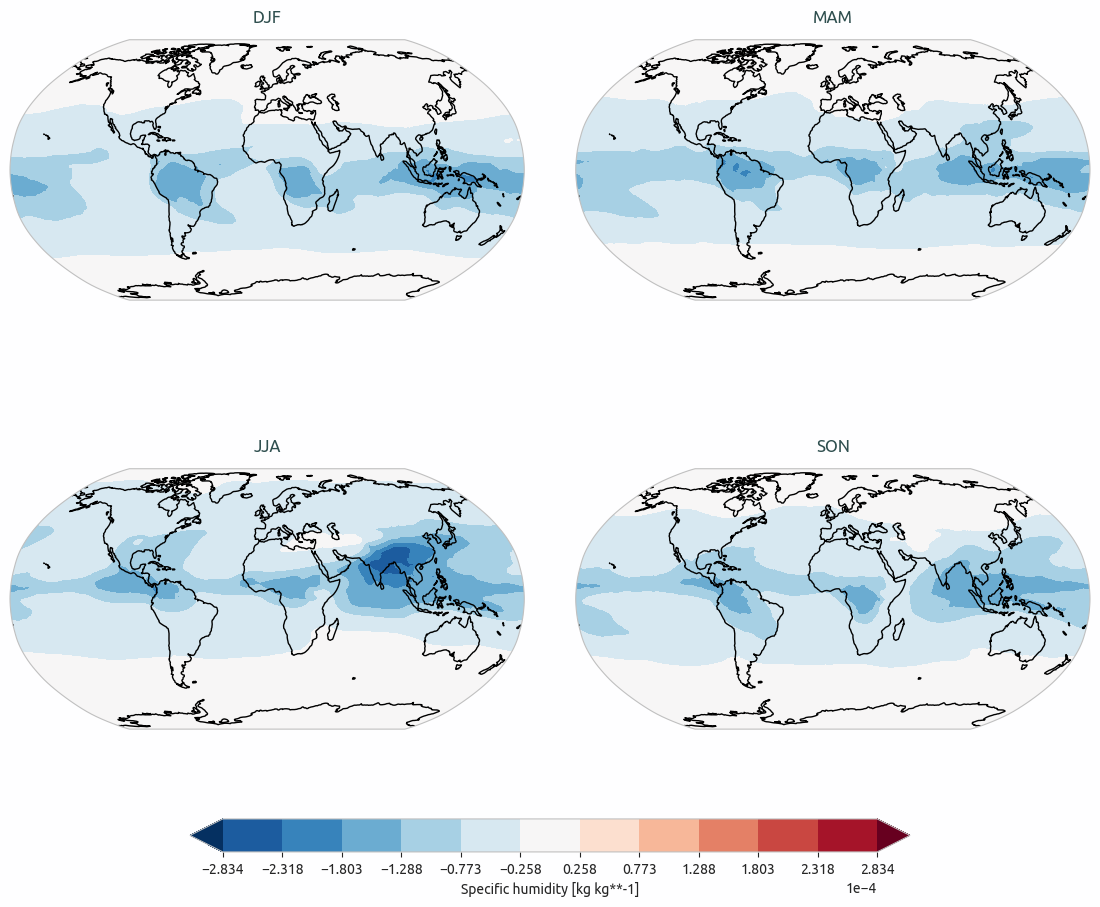
Seasonal bias of q from IFS-NEMO historical-1990 with respect to ERA5 climatology.
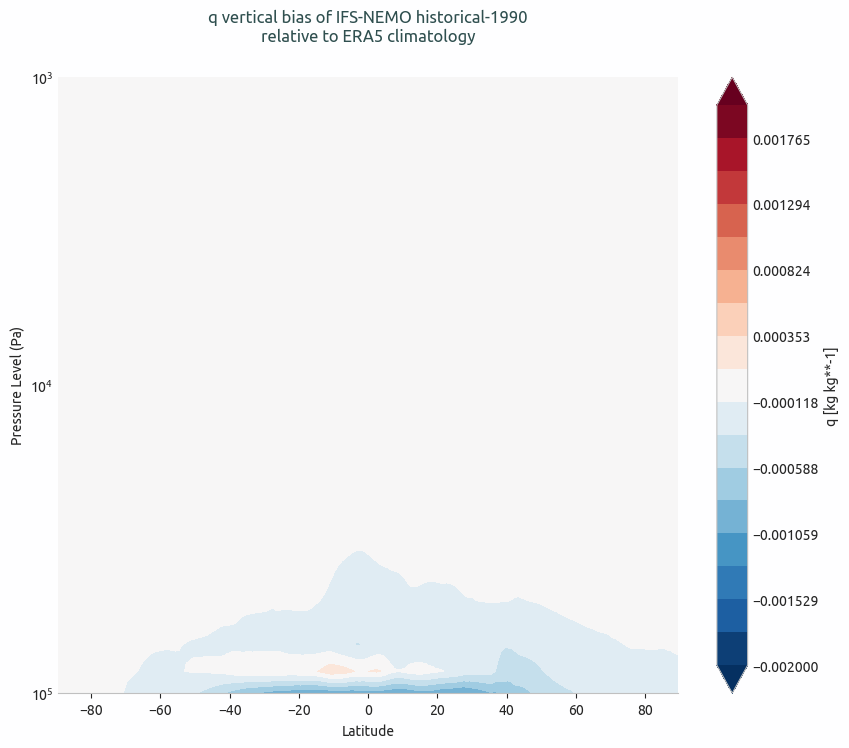
Vertical bias of q from IFS-NEMO historical-1990 with respect to ERA5 climatology.
Available demo notebooks
Notebooks are stored in notebooks/diagnostics/global_biases:
Detailed API
This section provides a detailed reference for the Application Programming Interface (API) of the global_biases diagnostic,
produced from the diagnostic function docstrings.
- class aqua.diagnostics.global_biases.GlobalBiases(catalog=None, model=None, exp=None, source=None, regrid=None, startdate=None, enddate=None, var=None, plev=None, areas=True, diagnostic='globalbiases', save_netcdf=True, outputdir='./', loglevel='WARNING')
Bases:
DiagnosticDiagnostic class for computing global and seasonal climatologies of a given variable.
This class handles data retrieval, pressure level selection, unit conversion, and computation of mean climatologies (total or seasonal).
Inherits from Diagnostic.
- Parameters:
catalog (str) – The catalog to be used. If None, inferred from Reader.
model (str) – Model to be used.
exp (str) – Experiment name.
source (str) – Source name.
regrid (str) – Target grid for regridding. If None, no regridding.
startdate (str) – Start date for data selection.
enddate (str) – End date for data selection.
var (str) – Variable name to analyze.
plev (float) – Pressure level to select (if applicable).
areas (bool) – if True, save area weights for statistics computation.
diagnostic (str) – Name of the diagnostic.
save_netcdf (bool) – If True, saves output climatologies.
outputdir (str) – Output directory for NetCDF files.
loglevel (str) – Log level. Default is ‘WARNING’.
Initialize the diagnostic class. This is a general purpose class that can be used by the diagnostic classes to retrieve data from a single model and to save the data to a netcdf file. It is not a working diagnostic class by itself.
- Parameters:
model (str) – The model to be used.
exp (str) – The experiment to be used.
source (str) – The source to be used.
catalog (str) – The catalog to be used. If None, the catalog will be determined by the Reader.
regrid (str | None) – The target grid to be used for regridding. If None, no regridding will be done.
startdate (str | None) – The start date of the plot/analysis period. If None, all available data will be used.
enddate (str | None) – The end date of the plot/analysis period. If None, all available data will be used.
std_startdate (str | None) – The start date of the standard deviation period. If None, no std period is tracked at the Diagnostic level.
std_enddate (str | None) – The end date of the standard deviation period. If None, no std period is tracked at the Diagnostic level.
loglevel (str) – The log level to be used. Default is ‘WARNING’.
- MINIMUM_MONTHS_REQUIRED = 12
- compute_climatology(data: Dataset = None, var: str = None, plev: float = None, save_netcdf: bool = None, seasonal: bool = False, seasons_stat: str = 'mean', areas=False, create_catalog_entry: bool = False) None
Compute total and optionally seasonal climatology for a variable.
- Parameters:
data (xarray.Dataset, optional) – Input dataset. If None, uses self.data.
var (str, optional) – Variable name. If None, uses self.var.
plev (float, optional) – Pressure level (currently unused).
save_netcdf (bool, optional) – If True, save output to NetCDF.
seasonal (bool) – If True, compute seasonal climatology (DJF, MAM, JJA, SON).
seasons_stat (str) – Aggregation statistic: ‘mean’, ‘std’, ‘max’, ‘min’.
areas (bool) – If True, include cell area in the output dataset.
create_catalog_entry (bool) – If True, create a catalog entry for the data. Default is False.
- Raises:
ValueError – If seasons_stat is invalid.
- retrieve(var: str = None, formula: bool = False, long_name: str = None, short_name: str = None, plev: float = None, units: str = None, reader_kwargs: dict = {}) None
Retrieve and preprocess dataset, selecting pressure level and/or converting units if needed.
- Parameters:
var (str, optional) – Variable to retrieve. If None, uses self.var.
formula (bool) – If True, the variable is a formula.
long_name (str) – The long name of the variable, if different from the variable name.
short_name (str) – The short name of the variable, if different from the variable name.
plev (float, optional) – Pressure level to extract.
units (str) – The units of the variable, if different from the original units.
reader_kwargs (dict, optional) – Additional keyword arguments for the Reader.
- Raises:
NoDataError – If variable not found in dataset.
KeyError – If the variable is missing from the data.
- savenetcdf(data: Dataset, diagnostic_product: str, rebuild: bool = True, create_catalog_entry: bool = False, extra_keys=None, dict_catalog_entry: dict = {'jinjalist': ['realization'], 'wildcardlist': ['var']})
Save data to NetCDF with proper metadata.
- Parameters:
data (xr.Dataset) – Input dataset.
diagnostic_product (str) – The product name to be used in the filename (e.g., ‘annual_climatology’).
rebuild (bool) – If True, rebuild the data from the original files.
create_catalog_entry (bool) – If True, create a catalog entry for the data. Default is False.
extra_keys (dict) – Extra keys for filename generation.
dict_catalog_entry (dict) – A dictionary with catalog entry information. Default is {‘jinjalist’: [‘freq’, ‘region’, ‘realization’], ‘wildcardlist’: [‘var’]}.
- class aqua.diagnostics.global_biases.PlotGlobalBiases(diagnostic='globalbiases', save_format=['png', 'pdf', 'svg'], dpi=300, outputdir='./', cmap='RdBu_r', return_fig: bool = False, loglevel='WARNING')
Bases:
objectInitialize the PlotGlobalBiases class.
- Parameters:
diagnostic (str) – Name of the diagnostic.
save_format (str or list) – Format(s) to save the figures. Default is SAVE_FORMAT.
dpi (int) – Resolution of saved figures.
outputdir (str) – Output directory for saved plots.
cmap (str) – Colormap to use for the plots.
return_fig (bool) – Whether plotting methods should return the figure and axes.
loglevel (str) – Logging level.
- plot_bias(data, data_ref, var, plev=None, proj='robinson', proj_params={}, vmin=None, vmax=None, cbar_label=None, area=None, show_stats=False, data_timeseries=None, data_ref_timeseries=None, show_significance=False, significance_alpha=0.05, stipple_density=None, stipple_size=0.8, target_spacing_deg=2, invert_stippling=False)
Plots the bias map between two datasets.
- Parameters:
data (xarray.Dataset) – Primary dataset.
data_ref (xarray.Dataset) – Reference dataset.
var (str) – Variable name.
plev (float, optional) – Pressure level.
proj (str, optional) – Desired projection for the map.
proj_params (dict, optional) – Additional arguments for the projection.
vmin (float, optional) – Minimum colorbar value.
vmax (float, optional) – Maximum colorbar value.
cbar_label (str, optional) – Label for the colorbar.
area (xr.DataArray, optional) – Grid cell areas for computing weighted statistics.
show_stats (bool, optional) – Whether to show statistical information on the plot.
data_timeseries (xr.Dataset, optional) – Model dataset with time dimension, used for significance testing.
data_ref_timeseries (xr.Dataset, optional) – Reference dataset with time dimension, used for significance testing.
show_significance (bool, optional) – Whether to overlay significance stippling on the plot. Default is False.
significance_alpha (float, optional) – Significance level for the t-test. Default is 0.05.
stipple_density (int, optional) – Subsampling factor for stippling. If None, computed adaptively.
stipple_size (float, optional) – Size of the stipple dots. Default is 0.8.
target_spacing_deg (float, optional) – Desired approximate spacing in degrees between plotted stipples when stipple_density is None. Default is 2.0.
invert_stippling (bool, optional) – If True, stipple where the bias is not significant. Default is False.
- plot_climatology(data, var, plev=None, proj='robinson', proj_params={}, vmin=None, vmax=None, cbar_label=None)
Plots the climatology map for a given variable and time range.
- Parameters:
data (xarray.Dataset) – Climatology dataset to plot.
var (str) – Variable name.
plev (float, optional) – Pressure level to plot (if applicable).
proj (string, optional) – Desired projection for the map.
proj_params (dict, optional) – Additional arguments for the projection (e.g., {‘central_longitude’: 0}).
vmin (float, optional) – Minimum color scale value.
vmax (float, optional) – Maximum color scale value.
cbar_label (str, optional) – Label for the colorbar.
- Returns:
Matplotlib figure and axis objects.
- Return type:
tuple
- plot_seasonal_bias(data, data_ref, var, plev=None, proj='robinson', proj_params={}, vmin=None, vmax=None, cbar_label=None)
Plots seasonal biases for each season (DJF, MAM, JJA, SON).
- Parameters:
data (xarray.Dataset) – Primary dataset.
data_ref (xarray.Dataset) – Reference dataset.
var (str) – Variable name.
plev (float, optional) – Pressure level.
proj (str, optional) – Desired projection for the map.
proj_params (dict, optional) – Additional arguments for the projection.
vmin (float, optional) – Minimum colorbar value.
vmax (float, optional) – Maximum colorbar value.
cbar_label (str, optional) – Label for the colorbar.
- Returns:
The resulting figure.
- Return type:
matplotlib.figure.Figure
- plot_vertical_bias(data, data_ref, var, plev_min=None, plev_max=None, vmin=None, vmax=None, vmin_contour=None, vmax_contour=None, nlevels=18)
Calculates and plots the vertical bias between two datasets.
- Parameters:
data (xarray.Dataset) – Dataset to analyze.
data_ref (xarray.Dataset) – Reference dataset for comparison.
var (str) – Variable name to analyze.
plev_min (float, optional) – Minimum pressure level.
plev_max (float, optional) – Maximum pressure level.
vmin (float, optional) – Minimum colorbar value.
vmax (float, optional) – Maximum colorbar value.
vmin_contour (float, optional) – Minimum contour value.
vmax_contour (float, optional) – Maximum contour value.
nlevels (int, optional) – Number of contour levels for the plot.
- class aqua.diagnostics.global_biases.StatGlobalBiases(loglevel: str = 'WARNING')
Bases:
objectClass for computing bias statistics between model and reference data. It works directly with xarray datasets and includes statistical significance testing.
- Parameters:
loglevel (str) – Log level. Default is ‘WARNING’.
- compute_bias_statistics(data: Dataset, data_ref: Dataset, var: str, area: DataArray = None) Dataset
Compute global mean bias and RMSE between model and reference data.
- Parameters:
data (xr.Dataset) – Model climatology dataset.
data_ref (xr.Dataset) – Reference climatology dataset.
var (str) – Variable name.
area (xr.DataArray, optional) – Grid cell areas for weighted statistics. If None, unweighted statistics will be computed.
- Returns:
Dataset containing mean bias and RMSE.
- Return type:
xr.Dataset
- compute_significance_ttest(data: Dataset, data_ref: Dataset, var: str, alpha: float = 0.05, min_samples: int = 3) DataArray
Compute statistical significance of bias using two-sample t-test.
Performs a two-sided t-test at each grid point to determine if the difference between model and reference data is statistically significant.
- Parameters:
data (xr.Dataset) – Model dataset with time dimension.
data_ref (xr.Dataset) – Reference dataset with time dimension.
var (str) – Variable name.
alpha (float) – Significance level (default: 0.05 for 95% confidence).
min_samples (int) – Minimum number of samples required to perform test. Default is 3.
- Returns:
- Boolean array where True indicates statistically significant differences.
Same spatial dimensions as input data.
- Return type:
xr.DataArray
- compute_yearly_temporal_means(data: Dataset, var: str) DataArray
Compute yearly temporal means for a given variable.
- Parameters:
data (xr.Dataset) – Input dataset with time dimension.
var (str) – Variable name to compute means for.
- Returns:
Yearly temporal means of the variable.
- Return type:
xr.DataArray
- ttest_at_grid_point(model_vals, ref_vals, min_samples: int = 3)
Perform t-test at a single grid point.
- Parameters:
model_vals (np.ndarray) – 1D array of model values at a grid point.
ref_vals (np.ndarray) – 1D array of reference values at the same grid point.
min_samples (int) – Minimum number of samples required to perform the t-test. Default is 3.
- Returns:
p-value from the t-test.
- Return type:
float